
cTenBigSort
一. 经典开场✅
二.概念✅
排序是数据处理的基本操作之一,每次算法竞赛都很多题目用到排序。排序算法是计算机科学中基础且常用的算法,排序后的数据更易于处理和查找。在计算机发展的历程中,在排序算法的研究一直深受人们重视,出现了很多算法,在思路、效率、应用等方面各有特色。通过学习排序算法,读者可以理解不同算法的优势和局限性,并根据具体情况选择最合适的算法,以提高程序的性能和效率。学习排序算法还有助于培养逻辑思维和问题解决能力,在解决其他类型的问题时也能够应用到类似的思维方法。
三.十大排序
选择排序🎈
选择排序(Selection Sort)是最简单、直观的排序算法,虽然效率不高,但是利于理解和实现。
排序的目的是什么?例如对n个数从小到大排序,就是把杂乱无序的n个数放到它们应该放的位置上。
最直接的做法是找到最小数,放在第1个位置,找到第2个小的数,放在第2个位置,......,找到第n个数,放在第n个位置。
这个思路就是排序,具体操作描述如下:
(1)第一轮,在n个数中找到最小数,然后与第1个位置的数交换,这样就把最小数放到了第一位置,如下图所示:

(2)第二轮,在第2~n个数中找到最小值,然后与第2个位置的数交换,这样就把地2小的数放到了第2个位置,如下图所示:
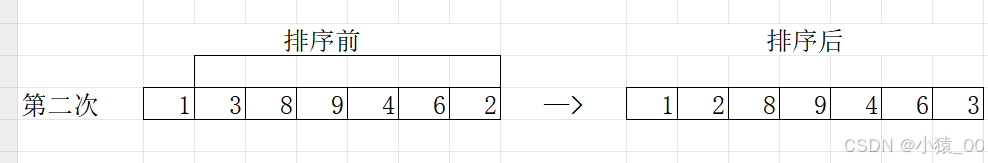
(3)第三轮,在第3~n个数中找到最小的数...... 一共执行n-1轮操作,第i轮找到第i小的数,放到第i个位置,就排好序了。
代码实现✅
直接写✨
1 |
|
函数✨
1 |
|
总结✅
选择排序算法的计算量是多少?找最小的数需要比较n-1次,找第2小的数需要比较n-2次,......,一共需要比较n^2/2次,把它的计算复杂度记为O(n^2)。直接看代码也能得到这个结论:有两重for循环,分别循环n次,共循环O(n^2)次。
将上述代码提交到判题系统,只能通过20%的测试。判题系统一般给一秒的执行时间,计算机一秒约能计算一亿次。本题20%的数据,有n<=10^3,能在一秒内完成。若n=10^5,选择排序需要的计算n^2=100亿次,超时。
选择排序是一种“死脑筋”的算法,它与数据列的特征无关,不管原数据列是不是有序,都得计算O(n^2)次,上一个“冒泡算法”就聪明得多,如果第一能找到最大数发现数列已经有序,就停止不再做排序计算。
选择排序虽然低效,但也有优点:(1)简单、易写;(2)不占用额外的空间,排序就在原理的序列上操作。
插入排序🎈
插入排序(Insertion Sort)是一种“动态”算法,在一个有序数列上这个增加数据,当新增一个数x时,把它插到有序数列中的合适位置,使数列扔保持有序。初始的数列是空的,这个插入所有的n个数据后,这n个数据就排好了序。
如何把x插到合适的位置?简单的做法是从有序数列的最后一个开始,逐个与x比较,若这个数比x大,就继续往前找,直到找到比x小的数,把x插到它的后面。
具体操作{12, 11, 13, 5, 6}为例,如下图所示:
(1)从第一个数a[0]开始,它构成了长度为1的有序数列a[0]。

(2)新增a[1],把它插到有序数列{a[0]}中。
若a[1]>a[0],完成,
若a[1] (3)新增a[2],把它插到有序数列{a[0], a[1]}中。
插入排序的计算复杂度取决于第5行的for循环和第8行的while循环,这是两重循环,各循环O(n)次,总计算复杂度O(n^2)。
冒泡排序(Bubble Sort)也是一种简单、直观的排序算法,它的算法思想和选择排序差不多,略有区别。
代码实现✅
直接写✨
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
int main() {
int arr[] = {12, 11, 13, 5, 6}; // 原始数组
int n = sizeof(arr) / sizeof(arr[0]); // 数组大小
int i;
// 插入排序实现
for ( i = 1; i < n; i++) {
int key = arr[i]; // 当前待插入的元素
int j = i - 1;
// 将大于key的元素移到右侧
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
// 插入当前元素到正确的位置
arr[j + 1] = key;
}
// 打印排序后的数组
printf("排序后的数组: \n");
for (i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}函数✨
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
void insertionSort(int arr[], int n) {
int i, key, j;
// 从第二个元素开始,遍历整个数组
for (i = 1; i < n; i++) {
key = arr[i]; // 当前待插入的元素
j = i - 1;
// 将大于key的元素移到右侧
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
// 插入当前元素到正确的位置
arr[j + 1] = key;
}
}
void printArray(int arr[], int n) {
int i;
for ( i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main() {
int arr[] = {12, 11, 13, 5, 6}; // 原始数组
int n = sizeof(arr) / sizeof(arr[0]); // 数组大小
insertionSort(arr, n); // 调用插入排序函数
printf("排序后的数组: \n");
printArray(arr, n); // 打印排序后的数组
return 0;
}总结✅
插入排序是不是和冒泡排序一样“聪明”?也就是说,如果待排序的数列已经有序了,再运行插入排序算法,插入排序是否知道已经排好序?此时第8行的while的判断条件a[i]>key始终不成立,while内的不会执行,而实际上就是a[i]=key,没有任何变化。也就是说,再次插入都是插到末尾,不用插到中间。那么for、while这两重循环实际上变成了只有for一个循环,一共计算O(n)次即结束。所以插入排序和“冒泡”排序一样“聪明”。
冒泡排序🎈
第一轮,找到最大的数,放到第n个位置:
第二轮,找到第2大的数,放到第n-1个位置;
......
第n轮,找到最小的数,放到第1个位置。
与选择排序的原理过于简单相比,冒泡排序用到了“冒泡”这个小技巧。以“第一轮,找最大的数,放到第n个位置”为例,对a[0]~a[n-1]做冒泡排序,操作如下:
(1)从第1个数a[0]开始,比较a[0]和a[1],如果a[0]>a[1],交换。进一步把前面两个数的最大数放到了第2个位置,如下图所示。
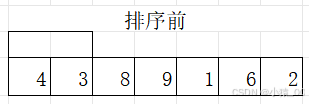
 (2)比较a[1]和a[2],如果a[1]>a[2],交换,这一步把前面3个数的最大数放到了第3个位置,如下图所示: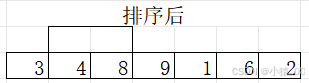
 (3)比较a[2]和a[3]…..
  依次比较相邻的两个数,直到最后两个数a[n-2]和a[n-1],就把最大的数放到了第a[n-1]个位置。一共比较了n-1次。
  将这个过程形象地比喻为“冒泡”,最大的元素像气泡一样慢慢“浮”到了顶端。
  以上是“第一轮,最大元素的冒泡”,其他的数也同样的方法处理,一共做n-1轮冒泡。第i轮找到第i大的数,冒泡到a[i-1],就把第i大的数放到了第i个位置。
代码实现✅
直接写✨
1 |
|
函数✨
1 |
|
总结✅
冒泡排序的计算复杂度:第5行和第8行有两重for循环计算复杂度为O(n^2),和选择排序的计算复杂度一样。
冒泡排序可以做一点优化:若两个相邻的数已经有序,那么不用冒泡;在第i轮求第i大的数时,若一次冒泡都没有发生,说明整个数列已经有序,算法结束。
 微信
微信 支付宝
支付宝



