
Python + Echarts + Mysql 实现大屏数据可视化

一、前言
简介
💻 时间稍纵即逝,转眼间大三就来到第二个学期,还有一学年就要毕业了;马上也要开始准备 毕业设计 。 但是很多地方还需要进阶学习。然后这段时间的也是对数据可视化进行学习,且做出了自己的作品之一,让我也是收获颇满;但同时也 认识到了自己的不足,下面我将介绍一下做的一些内容。
项目整体设计思路
🌤️ 首先通过数据的爬取并且存入数据库;其次就是前端使用flex布局,最后将想要的数据进行展示.
项目在改变生活中的应用场景
🌥️ 在很多公司中,很多的地方需要使用数据可视化来对数据进行简单的分析和展示; 生活中应用的场景:比如淘宝的数据、疫情的数据、电商数据等很多方面都会使用到数据可视化.
二、开发工具
🔎 Pycharm + Navicat + Echarts
三、涉及技术栈
Python
💌 Python是一个高层次的结合了 解释性、编译性、互动性和面向对象 的脚本语言。Python 是由荷兰人吉多·罗萨姆于 1989 年发布的。 在这里我也就不多讲解释,需要学习请自己多看Python官方
Flask
🗒️️ Flask框架是Python的一个轻量级框架,用起来方便。当然,想学会Flask框架之前一定要学会最基本的Web三件套HTML5,CSS3,JavaScript 这三个基本的技术是必备的前提,不然后期使用起来就会有点费劲。Flask框架的架构也是采用 MVC 方式和ThinkPHP一样,这里我就不多进行讲述了,需要学习 ThinkPHP官网进行学习。 MVC代表的是什么呢?M代表的是:模型;V代表的是:视图;C代表的是:控制器层。
Ajax
🖱️ AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 不是新的编程语言,而是一种使用现有标准的新方法。 AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。 AJAX 不需要任何浏览器插件,但需要用户允许 JavaScript 在浏览器上执行。
网络爬虫
⭕目前我学习了两种爬虫方法,一种是 Request。另一种是通过 Selenium 包对网页的数据进行爬取.两者都可以实现数据的爬取,但是两者有很明确的优缺点;Request爬取数据的 速度很快,但是要对应的接口,否者拿不到想要的数据.但是Selenium包可以通过浏览器对网页进行抓取数据,很方便但是速度上面有明显的劣势.
⭕小建议 避坑 :当我们进行网络爬虫前一定要多去过几次HTTP返回的状态码;这个真的很重要,如果我们对状态码都不是很清楚的话,有时候对于浏览器放回的值 就会产生看不懂的情况,就会很迷茫.所以,浏览器最基本的几个状态码一定要记得:
Selenium
️💦 Selenium 是一款用于Web应用程序测试的工具,它支持多平台、多语言、多浏览去实现自动化测试。通过Selenium这对网页的数据进行提取, 当然提取也需要对元素进行定位,那么定位怎么弄呢,别急往下看!
Xpath
XPath 全称 XML Path Language ,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言 它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索 XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理几乎所有我们想要定位的元素 都可以通过Xpath进行定位.这里也就和上面的Selenium进行了一个解释.
Echarts
Echarts 是一个使用 JavaScript 实现的开源可视化库,涵盖各行业图表,满足各种需求。 需要学习的可以看一下 Echarts官网
Mysql
Mysql 是一个数据库,我想学习计算机专业都知道这个东西,和他打交道的时间相对来说还是比较多的。我们这里为什么要去使用 Mysql呢?我们前面这些操作都是为了对数据的来源做准备,如果数据没有,我们后期的工作就只能说为零;所以,我们通过上述的一切就是为了 把数据得到并且把数据放入数据库做铺垫。如果没有数据库对数据进行分析(除了Excel)就有一定的困难,通过数据库我们在Flask框架中的 模型层对数据进行聚合查询,从数据库中得到自己想要的数据; 再通过控制器层得到的数据进行放回给视图层,从而实现将数据动态的传送前台页面。
四、可视化界面
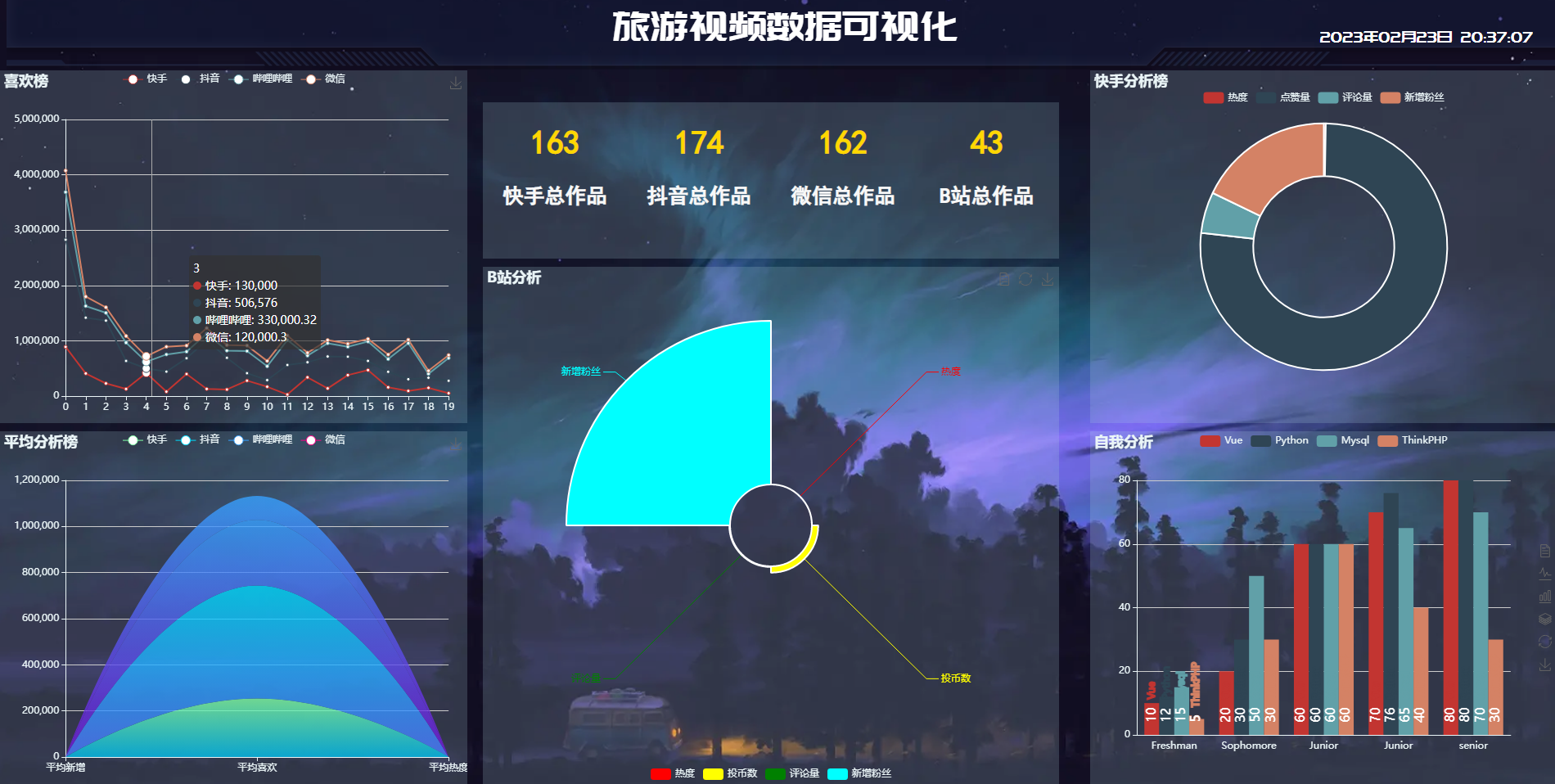
项目地址:
五、总结
看了上述的文章如果对你来说有一定的帮助, 请别忘了给小猿一点鼓励!
通过这次的一个实战,我也对自己的软板有了一定的了解,同时对前后端交互数据、请求好像有了进一步的的了解; 视频学习地址: 点击前往
 微信
微信 支付宝
支付宝







